|
Features
|
|||||||||
|
Minimum # Drives
|
2
|
2
|
3
|
3
|
4
|
||||
|
Data Protection
|
No Protection
|
Single-drive failure
|
Single-drive failure
|
Single-drive failure
|
Single-drive failure
|
||||
|
Read Performance
|
High
|
High
|
High
|
High
|
High
|
||||
|
Write Performance
|
High
|
Medium
|
Medium
|
Low
|
Low
|
||||
|
Read Performance (degraded)
|
N/A
|
Medium
|
High
|
Low
|
Low
|
||||
|
Write Performance (degraded)
|
N/A
|
High
|
High
|
Low
|
Low
|
||||
|
Capacity Utilization
|
100%
|
50%
|
50%
|
67% - 94%
|
50% - 88%
|
||||
|
Typical Applications
|
High End Workstations, data logging, real-time rendering, very
transitory data
|
Operating System, transaction databases
|
Operating system, transaction databases
|
Data warehousing, web serving, archiving
|
Data warehousing, web serving, archiving
|
||||
|
Features
|
|||||||||
|
Minimum # Drives
|
4
|
4
|
6
|
8
|
|||||
|
Data Protection
|
Two-drive failure
|
Up to one disk failure
in each sub-array
|
Up to one disk failure
in each sub-array
|
Up to two disk failure
in each sub-array
|
|||||
|
Read Performance
|
High
|
High
|
High
|
High
|
|||||
|
Write Performance
|
Low
|
Medium
|
Medium
|
Medium
|
|||||
|
Read Performance (degraded)
|
Low
|
High
|
Medium
|
Medium
|
|||||
|
Write Performance (degraded)
|
Low
|
High
|
Medium
|
Low
|
|||||
|
Capacity Utilization
|
50% - 88%
|
50%
|
67% - 94%
|
50% - 88%
|
|||||
|
Typical Applications
|
Data archive, backup to disk, high availability solutions,
servers with large capacity requirements
|
Fast databases, application servers
|
Large databases, file servers, application servers
|
Data archive, backup to disk, high availability solutions,
servers with large capacity requirements
|
|||||
The write
penalty of RAID 5
By Rickard Nobel | August 2, 2011
Compared to other RAID levels we have a higher write overhead in
RAID 5. In this article we will see in some detail why there is a larger
“penalty” for writing to RAID 5 disk systems.

In a RAID 5 set with any number of disks we will calculate a parity information for each stripe. See this article on how the RAID 5 parity works. In short, we use the XOR operation on all binary bits on all disks and save the result on the parity disk. For example if we have an eight disk set the actual data is saved on seven disks and parity on the last disk, see picture above.
A disadvantage with RAID 5 is how to write small IOs against the disk system. Even if
the write IO will only affect the data on one disk, we still need to calculate
the new parity. Since the parity, as explained in the other article, is created
by using XOR on all disks this could now be
done in two ways. We could either do a read against all the other disks and
then XOR with the new information. This would however cause a very large
overhead and it is not reasonable to block all other disks for just one write.
There is however a
quite clever way to calculate the new parity with a minimum of disk IO.
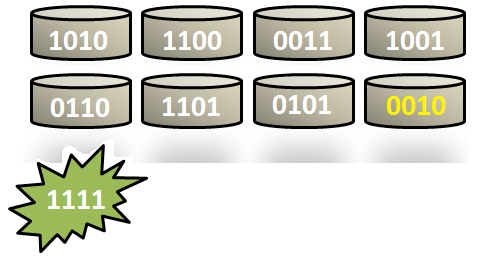
Assume we have the following eight disks and a write should be
done at the fifth disk, which should be changed to, say, 1111. (For simplicity we will only look at four bits at
each disk, but this could be of any size.)
To get the new parity some actions has to be done. First we read the old data on the blocks that should be
changed. We can call this “Disk5-Old” and will
be the first IO that must be done. The data that should be written, here 1111,
can be called Disk5-New.
Disk5-0ld = 0110
Disk5-New = 1111
Disk5-New = 1111
We will now use XOR on the old and the new data, to calculate
the difference between the old and new. We can call this Disk5-Delta.
Disk5-Delta =
Disk5-Old XOR Disk5-New = 0110 XOR 1111 = 1001
When we know the “delta” we will have to commit another read. This
is against the old parity. We call this Parity-Old, in this
example the old parity is 0010. We will now
XOR the old parity with the Disk5-Delta. What is quite interesting is that this will create the new parity, but without the need
to read the other six disks.
Parity-New =
Parity-Old XOR Disk5-Delta = 0010 XOR 1001 = 1011
When we know the new
parity we can write both the new data block and the new parity. This causes two
write IOs against the disks and makes up the last of the “penalty”.
So in summary this
disk actions that must be done:
1. Read the old
data
2. Read the old parity
3. Write the new data
4. Write the new parity
2. Read the old parity
3. Write the new data
4. Write the new parity
This means that each write against a RAID 5 set causes four IOs against the disks where the first
two must be completed before the last two could be performed, which introduces
some additional latency.

 Following are the key points to remember for RAID level 1.
Following are the key points to remember for RAID level 1.
 Following are the key points to remember for RAID level 10.
Following are the key points to remember for RAID level 10.

